

想讓網站在 Google 上被看見,就必須先了解如何與搜尋引擎爬蟲溝通。本文將帶您深入解析 robots.txt 與 meta robots 這兩個 SEO 核心工具,從基本觀念到實戰應用,教您如何精準控制網站的檢索與索引,將寶貴的爬取預算花在刀口上,有效提升網站 SEO 體質。
我只想看重點:robots.txt 與 meta robots 3 大問答 1 分鐘搞懂
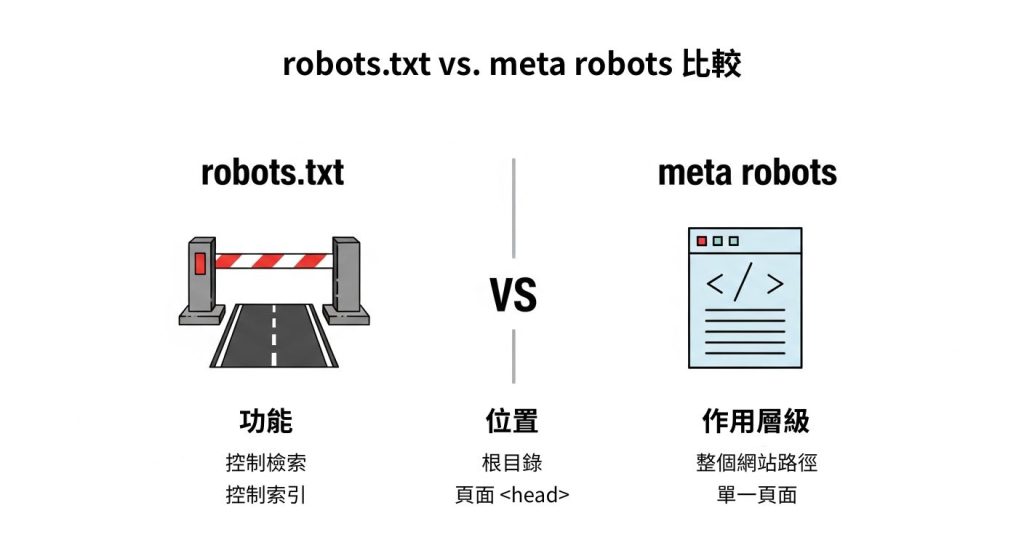
了解 robots.txt 與 meta robots 之前,先搞懂「檢索」與「索引」
在 SEO 的世界裡,一切都始於 Google 的「爬蟲」(Crawler 或 Bot)。當爬蟲造訪你的網站時,會先進行「檢索(Crawl)」,也就是讀取頁面內容;接著再決定是否將該頁面「索引(Index)」,也就是收入 Google 的巨大資料庫中,讓使用者有機會透過搜尋結果找到它。
👉 延伸閱讀:檢索、索引、排名是什麼?
在這個過程中,robots.txt 和 meta robots 就是你與爬蟲溝通的兩大工具。
可以這麼想:
- robots.txt 像是網站大門口的「訪客須知」,告訴爬蟲「哪些區域禁止進入」。
- meta robots 則像是每個房間裡的「內部備忘錄」,提醒爬蟲「這裡的內容可以看,但請不要公開」。

設定得當,就能讓 Google 專注在你真正想被看見的內容上,避免浪費爬取預算(Crawl Budget)在測試頁、草稿頁或後台頁等無關緊要的部分。
特別是對大型網站來說,每一分爬取預算都十分珍貴,這一步設定往往決定了整體 SEO 成效。
robots.txt 與 meta robots 有什麼不同?
許多人常常搞混 robots.txt 和 meta robots 的用途,但它們的功能其實截然不同,用錯了可能會對 SEO 造成災難。
- robots.txt:控制「檢索」(Crawl)
- 功能:這是一個純文字檔案,用來告訴搜尋引擎爬蟲「不要來爬取」網站上的特定路徑或檔案。如果一個頁面被 robots.txt 封鎖了,Googlebot 基本上會直接略過,連看都不會看。
- 時機:當您不希望爬蟲浪費時間在某些頁面時使用,例如網站後台(/wp-admin/)、內部測試頁面,或是會產生大量無價值頁面的篩選功能。
- meta robots:控制「索引」(Index)
- 功能:這是一段放在頁面 <head> 區域的 HTML 標籤,它允許爬蟲進來檢索頁面內容,但會告訴它「不要將此頁面放入搜尋結果中」。
- 時機:當頁面對網站有其必要性(例如:能帶來流量或內部連結價值),但本身不適合出現在搜尋結果時使用。常見的例子包括會員登入頁、購物車頁面、或站內搜尋結果頁。
💡專家建議:您可以這樣簡單地區分:robots.txt 是阻擋爬蟲進入的大門守衛,而 meta robots 是允許爬蟲進入,但要求它保密的指令。請記住,這兩者絕對不能混用在同一個目標頁面上,後續我們會解釋為什麼。
robots.txt 詳細教學:從基礎到實戰
robots.txt 的設定非常嚴謹,任何一個小錯誤都可能導致整個網站被搜尋引擎忽略。請務必遵守以下規則。
檔案格式與位置
robots.txt 必須是 純文字檔(UTF-8 編碼),檔名固定為 robots.txt,並放在網站的 根目錄(例如: https://yourwebsite.com/robots.txt)。
如果你有不同子網域(如 m.example.com),要各自放一份 robots.txt。
User-agent: *
Disallow: /private/
Allow: /public/
Sitemap: https://www.example.com/sitemap.xml- User-agent:指定要對哪個爬蟲下指令。* 代表所有爬蟲(AdsBot 除外),您也可以指定特定爬蟲,如 Googlebot 或 Bingbot。
- Disallow:禁止 User-agent 檢索的目錄或網頁。
- Allow:允許 User-agent 檢索的目錄或網頁,通常用於在一個被 Disallow 的目錄中,開放特定子目錄或檔案。
- Sitemap:告訴爬蟲您網站地圖的位置,幫助它更有效率地找到網站所有重要頁面。
💡專家小提醒:
Google 會優先採用「最明確的規則」,若同一頁同時被 Allow 與 Disallow,系統會選擇最寬鬆的那條。
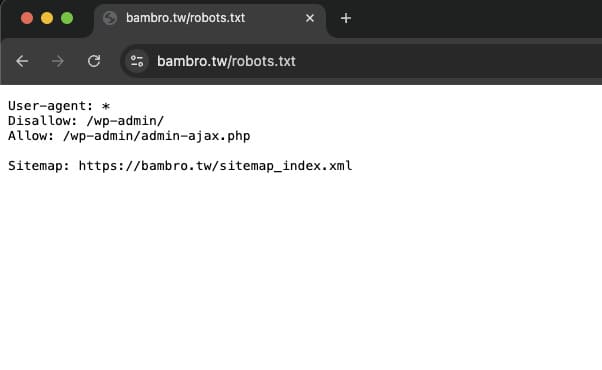
範例:一個常見的 WordPress 網站 robots.txt
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://yourwebsite.com/sitemap_index.xml這個範例的意思是:對所有爬蟲封鎖 「/wp-admin/」 後台目錄,但允許爬取其中一個重要的 「admin-ajax.php」 檔案,並提供網站地圖的路徑。
進階應用與注意事項
除了基本設定,「robots.txt」還能做更多事。例如,您可以利用它來阻擋 AI 訓練機器人爬取您的網站內容,或是禁止特定類型的檔案被檢索。
範例:阻擋 AI 爬蟲與特定檔案
# 阻擋 OpenAI 的爬蟲
User-agent: GPTBot
Disallow: /
# 阻擋特定檔案類型
User-agent: *
Disallow: /*.pdf$
Disallow: /private/- 第一個區塊明確指示 GPTBot 不要爬取網站任何內容。
- 第二個區塊則使用萬用字元 * 和結尾符號 $ 來禁止所有爬蟲檢索網站上所有結尾是 .pdf 的檔案。
💡專家建議:設定完成後,務必使用 Google 官方的「robots.txt 測試工具」來檢查語法是否正確,以及您想開放或封鎖的網址是否如預期般運作。一個錯誤的斜線 / 都可能導致災難性的後果!
meta robots 設定教學:精準的索引控制
當 robots.txt 不適合使用時,meta robots 標籤就是您的最佳選擇。它能更細緻地管理單一頁面的索引狀態。
設定方法與核心指令
您只需要將一段 meta 標籤加入到目標頁面的 <head> 區塊即可。對於使用 WordPress 或 Wix 等平台的使用者來說,通常可以透過 SEO 外掛或頁面設定輕鬆完成,完全不需要碰到程式碼。
HTML 範例
<meta name="robots" content="noindex, nofollow">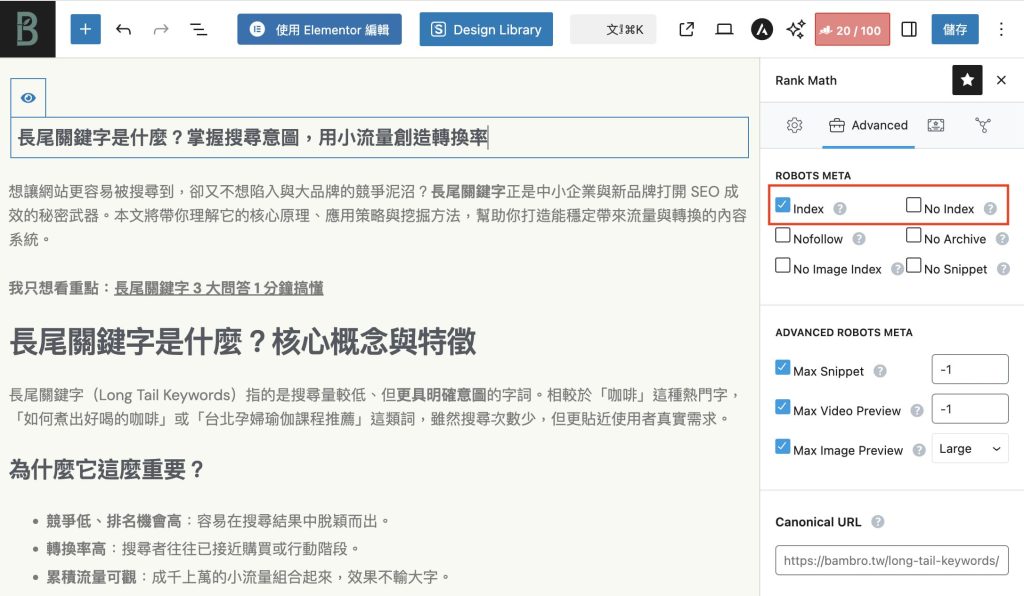
- name=”robots”:表示此規則適用於所有搜尋引擎。
- content=”…”:定義具體的指令,常見的有:
- noindex:禁止索引此頁面。這是最常用的指令。
- nofollow:禁止爬蟲跟隨此頁面上的任何連結,不將頁面權重傳遞出去。
- follow:允許爬蟲跟隨頁面上的連結(這是預設值)。
- nosnippet:禁止在搜尋結果中顯示此頁面的摘要或預覽。
💡專家建議:在大多數情況下,noindex, follow 是最實用且安全的組合。這代表您告訴 Google:「這個頁面不要出現在搜尋結果中,但頁面上的連結都是優質的,你可以去看看,並把權重傳遞過去。」這有助於維持網站內部的連結權重流動。
常見應用情境
noindex 標籤的應用場景非常廣泛,核心概念是「避免使用者從搜尋結果進到體驗不佳或無獨特價值的頁面」。
- 電商網站:購物車、結帳流程、會員中心等頁面,對使用者有功能性,但對搜尋引擎沒有索引價值。
- 內容網站:感謝頁、標籤或分類的封存頁面、作者列表頁,這些頁面內容較單薄或重複性高,不適合直接展示在搜尋結果中。
- 行銷活動頁面:某些僅針對特定客群的短期活動頁,不希望被大眾搜尋到。
透過 noindex,您可以確保使用者在 Google 上只會找到您精心準備、內容最豐富的頁面,從而提升品牌形象與使用者體驗。
實務建議與注意事項
1. 別用 robots.txt 隱藏敏感資訊
robots.txt 檔案是完全公開的,任何人都可以查看。如果您在裡面寫下 Disallow: /private/,反而告訴了所有人您的敏感路徑在哪。對於需要保密的頁面,請務必使用密碼保護等伺服器層級的驗證方式,並搭配 noindex 標籤。
2. 避免 robots.txt 與 meta robots 衝突
這是一個邏輯上的矛盾。如果您用 robots.txt 封鎖了一個頁面,Google 爬蟲就永遠無法進入該頁面,自然也看不到您放在頁面中的 noindex 標籤。
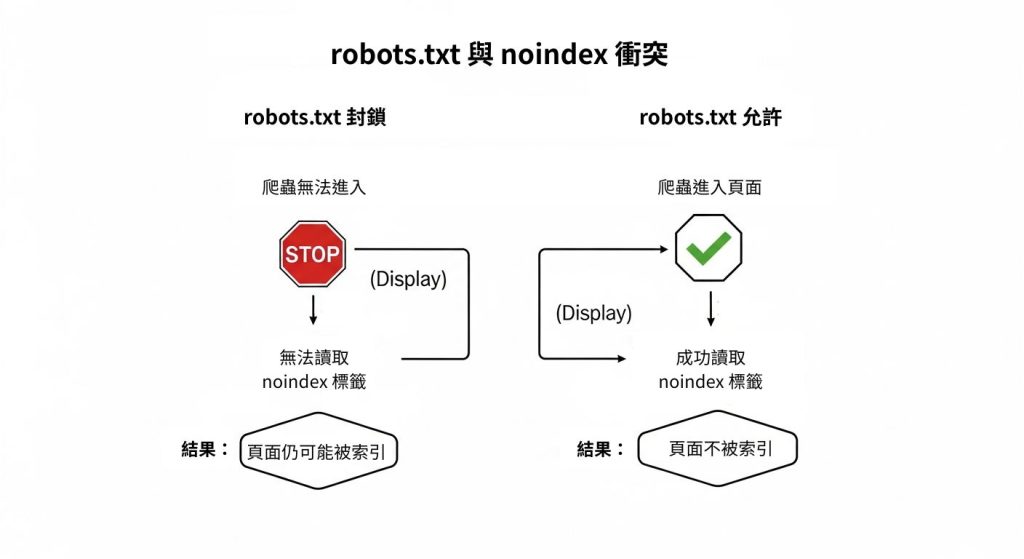
結果可能導致:即使 Google 沒有爬取頁面內容,但如果它從其他網站看到連至此頁面的連結,它仍然可能會為這個被封鎖的網址建立索引(只是搜尋結果會顯示「無法提供網頁摘要」)。正確的做法是,如果您希望一個頁面不被索引,請務必移除 robots.txt 中的封鎖規則,讓 Google 能順利讀取到 noindex 指令。
👉 延伸閱讀:Google Search Console 關於封鎖網址的說明
3. 小型網站設定建議
一般企業網站或部落格,只需確認 robots.txt 沒擋到該收錄的頁面即可。
Google 對優質內容仍會主動索引,不必過度干預設定。
善用 robots.txt 與 meta robots,讓搜尋引擎更懂你
robots.txt 與 meta robots 是控制網站曝光節奏的「隱形 SEO 助手」。妥善設定後,你不僅能讓 Google 更快抓取關鍵內容,也能避免重複頁、草稿頁或隱私頁干擾搜尋結果。
如果你經營的是品牌或內容型網站,建議定期檢查 robots.txt 是否阻擋了應曝光的頁面,並確保 meta robots 的設定與內容策略一致。
只有當搜尋引擎「看懂」你的網站,流量才會自然流向對的地方。
robots.txt 與 meta robots 3 大問答 1 分鐘搞懂
robots.txt 和 meta robots 差在哪?
你可以這樣想:
- robots.txt 是「門口警衛」:直接在網站大門口告訴 Google 爬蟲「這幾條路不准進來逛」。適合用來擋掉整個區域,像是網站後台 (/wp-admin/) 或測試區。
- meta robots 是「房間內的紙條」:讓爬蟲進來逛,但針對特定房間(頁面)貼上紙條說「這裡的資料看看就好,請不要 PO 到 Google 上(索引)」。
一句話總結:想讓 Google 連看都不看,用 robots.txt;想讓它看但不要收錄,用 meta robots。
哪些頁面不該出現在 Google 上,但又不能刪掉?
很多頁面對於網站功能或使用者體驗是必要的,但本身沒什麼 SEO 價值,不適合出現在搜尋結果。這時候就要用 meta robots 裡的 noindex 標籤把它們藏起來。
常見例子:
- 電商網站:購物車、結帳頁面、會員中心。
- 內容網站:訪客留言後的「感謝頁」、沒什麼內容的標籤頁、站內搜尋結果頁。
這些頁面如果被新訪客從 Google 直接搜到,只會覺得滿頭問號,所以最好把它們設定為 noindex。
我用 robots.txt 封鎖網址了,為什麼 Google 搜尋還找得到?
這是一個超常見的 SEO 致命錯誤!
robots.txt 是門口警衛。如果你不讓 Google 爬蟲進門,它就永遠看不到你貼在房間內的 noindex 紙條。
結果就變成:Google 雖然沒進來,但可能從別的網站連結看到這個網址,所以還是把它收錄了,只是搜尋結果會變得很奇怪(例如顯示「無法提供網頁摘要」)。
正確做法:如果你確定要用 noindex,就絕對要讓 Google 能爬到頁面,也就是 robots.txt 裡不能封鎖它!


